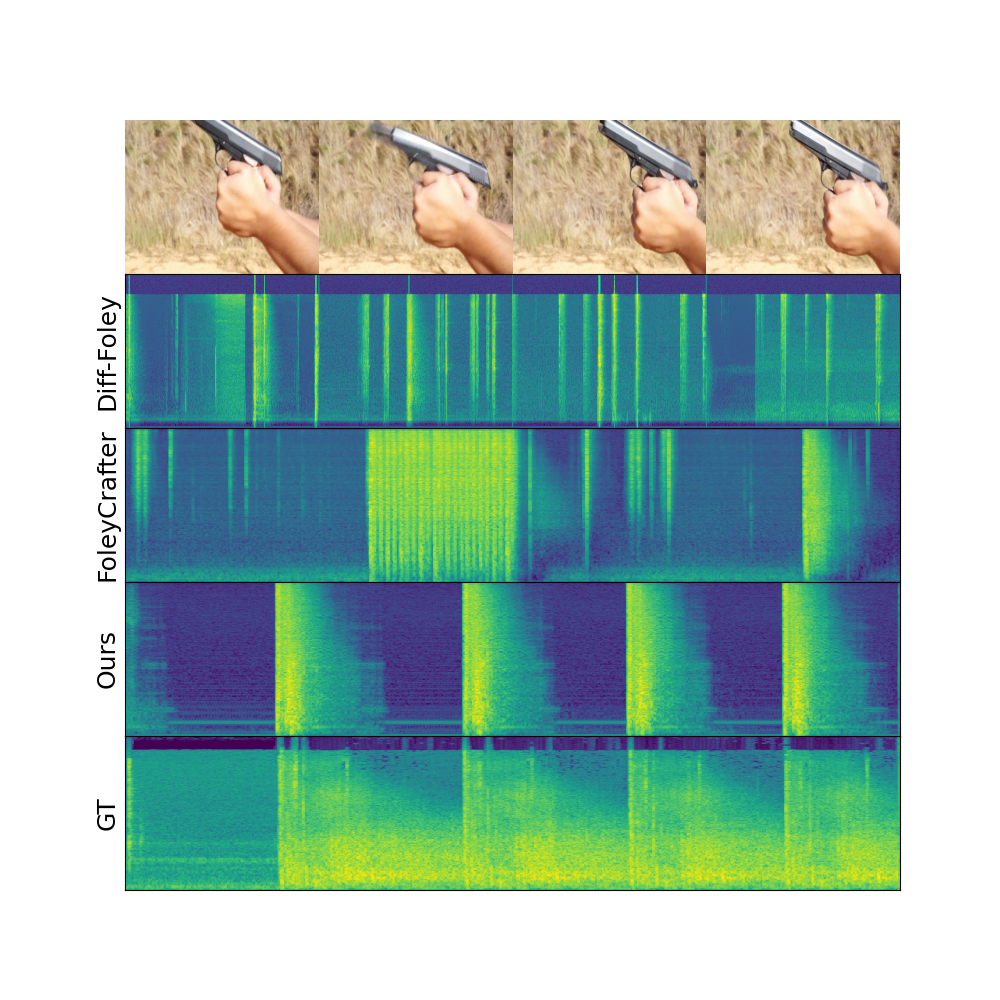
Generating sound effects for videos requires creating industry-standard sound effects that diverge significantly to produce high-quality audio generation in few-shot settings. To address this problem, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. The foundation model consists of two modules. The first module is a conditional flow matching transformer that builds a fine-grained, learnable Audio-Vision Aggregator (AVA) that integrates high-resolution visual features with corresponding audio features across multiple stages. The second module is a multi-modal visual-audio chain-of-thought framework that leverages advanced audio generation techniques to produce high-quality audio in few-shot settings. Finally, an industry-standard video-to-audio dataset that encompasses a diverse array of real-world scenarios is presented. Through both automated evaluations and human studies, we show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs, surpassing existing methods in performance.
Method
Figure 1: Overview of YingSound.
It comprises two key components: Conditional Flow Matching with Transformers and Adaptive Multi-modal Chain-of-Thought-Based Audio Generation.